Adding Relation Extraction to Renard: Part 1
I have been working on the 0.7 release of Renard (What is Renard?), with many new features and improvements. Among these, a new feature: Renard will now be able to extract relational character networks, networks where each edge is attributed with the types of relations between two characters. This blog post describes the beginning of the implementation of that feature.
New Steps
A Renard pipeline looks like this:
pipeline = Pipeline( [ NLTKTokenizer(), BertNamedEntityRecognizer(), GraphRulesCharacterUnifier(), T5RelationExtractor(), RelationalGraphExtractor(), ] )
Basically, it is a series of steps, each representing a natural language processing tasks, that leads to the extraction of a character network.
In the above pipeline, the first three steps already exists:
NLTKTokenizer cuts a text in tokens and sentences,
BertNamedEntityRecognizer performs NER to detect character mentions
and GraphRulesCharacterUnifier unifies these mentions into proper
characters.
The last two steps are new: T5RelationExtractor and
RelationalGraphExtractor. The first one extracts relationships
between characters that are found in the text, while the second
constructs the graph from all the previous information.
T5RelationExtractor
As its name indicates, this step uses the T5 sequence-to-sequence model to extract observed relations between characters in each sentence of the input text.
To train T5 on that task, I used the recent Artificial Relationships in Fiction (ARF) dataset (Christou, D. and Tsoumakas, G., 2025). This dataset contains 96 books, each with an average of 1337 relations. For example, given the following chunk of text:
It is true that Taug was no longer the frolicsome ape of yesterday. When his snarling-muscles bared his giant fangs no one could longer imagine that Taug was in as playful a mood as when he and Tarzan had rolled upon the turf in mimic battle. The Taug of today was a huge, sullen bull ape, somber and forbidding. Yet he and Tarzan never had quarreled. For a few minutes the young ape-man watched Taug press closer to Teeka.
The dataset provides the following annotations:
[
{
"entity1": "Taug",
"entity2": "Tarzan",
"entity1Type": "PER",
"entity2Type": "PER",
"relation": "companion_of",
},
{
"entity1": "Taug",
"entity2": "Teeka",
"entity1Type": "PER",
"entity2Type": "PER",
"relation": "companion_of",
},
]
I simplified that format to use classic semantic triples such as
(Taug, companion_of, Tarzan).
It might come as a surprise that relations are not annotated by humans in the ARF dataset. Rather, they are automatically extracted by GPT-4o, which may or may not be a problem for quality. This question is only lightly tackled by the authors in the original article, so it is hard to know the extent of that issue. While I could have written a module to make API calls to GPT-4o directly, I made the choice to distil its knowledge in a smaller specialized model that can be used with way less resources.
A possible question is, why use a generative model like T5? After all, we could formalize the problem as a multi-label classification problem and use an encoder model: for each pair of characters present in a chunk of text, output the list of relation labels. However, this would require a lot of inference calls (one per pair), so I turned to the generative paradigm instead, which seems more elegant in that case. But I did not compare both solutions, so this might be a wrong choice.
Training T5 in itself is rather straigthforward. For each example in the dataset, I use an input of the form:
prompt = f"extract relations: {chunk_of_text}"
And the labels are the semantic triples, for example:
"(Taug, companion_of, Tarzan), (Taug, companion_of, Teeka)"
For a first test, I finetuned T5-small for 5 epochs with a learning rate of 1e-4. After a ~45 min training on my RX 9070XT (AMD ROCm yay!), I got the following loss curve:
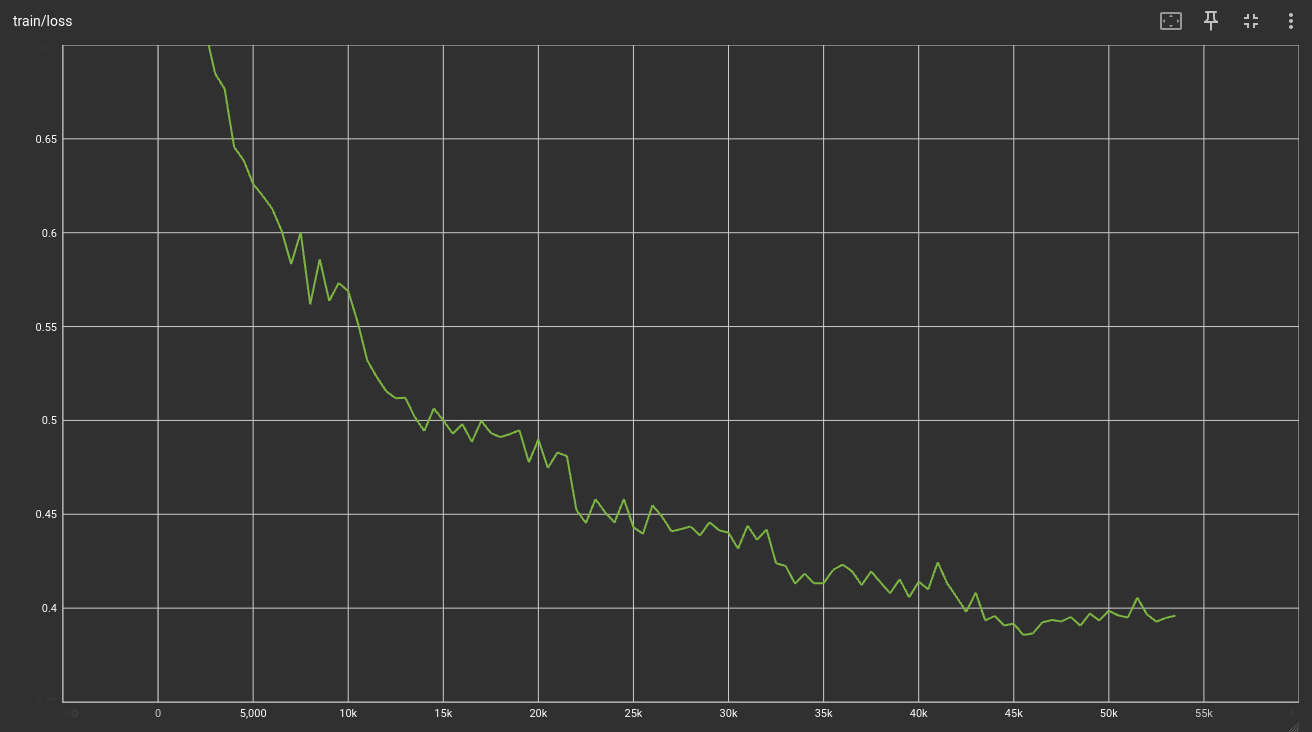
Ok, that looks decent. Let's see if it works:
from transformers import pipeline pipeline = pipeline("text2text-generation", model="compnet-renard/t5-small-literary-relation-extraction") text = "Zarth Arn is Shorr Kann enemy." pipeline(f"extract relations: {text}")[0]["generated_text"]
Which gives "(Zarth Arn, enemy_of, Shorr Kann)", good enough. I left
performance evaluation to a future weekend of work, so I don't have
any precise idea of the real performance of the model yet (I did not
compute test metrics except loss).
RelationalGraphExtractor
The RelationalGraphExtractor step is a simple component: given the
list of characters and the list of relations extracted for each
sentence of the text, create a network. This is easy enough using
networkx, so here's the entire Renard step:
class RelationalGraphExtractor(PipelineStep): def __init__(self, min_rel_occurrences: int = 1): self.min_rel_occurrences = min_rel_occurrences def __call__( self, characters: list[Character], sentence_relations: list[list[Relation]], **kwargs, ) -> dict[str, Any]: G = nx.Graph() for character in characters: G.add_node(character) edge_relations = defaultdict(dict) for relations in sentence_relations: for subj, rel, obj in relations: counter = edge_relations[(subj, obj)].get(rel, 0) edge_relations[(subj, obj)][rel] = counter + 1 for (char1, char2), counter in edge_relations.items(): relations = { rel for rel, count in counter.items() if count >= self.min_rel_occurrences } if len(relations) > 0: G.add_edge(char1, char2, relations=relations) return {"character_network": G} def supported_langs(self) -> Literal["any"]: return "any" def needs(self) -> set[str]: return {"characters", "sentence_relations"} def production(self) -> set[str]: return {"character_network"}
There is no support for dynamic networks yet, but since I located relations in each sentence, this is easily something I can add in the future.
The new steps in action
from renard.pipeline import Pipeline from renard.pipeline.tokenization import NLTKTokenizer from renard.pipeline.ner import BertNamedEntityRecognizer from renard.pipeline.character_unification import GraphRulesCharacterUnifier from renard.pipeline.relation_extraction import T5RelationExtractor from renard.pipeline.graph_extraction import RelationalGraphExtractor from renard.resources.novels import load_novel pipeline = Pipeline( [ NLTKTokenizer(), BertNamedEntityRecognizer(), GraphRulesCharacterUnifier(), T5RelationExtractor(), RelationalGraphExtractor(), ] ) novel = load_novel("pride_and_prejudice") out = pipeline(novel)
Mmh, that's a lot of import. Maybe someday I'll get to making something that looks less like some Java horror. At least, I added a new preconfigured pipeline for shorter code:
from renard.pipeline.preconfigured import relational_pipeline pipeline = relational_pipeline() novel = load_novel("pride_and_prejudice") out = pipeline(novel)
What does that look like in practice?
import matplotlib.pyplot as plt from renard.pipeline.preconfigured import relational_pipeline pipeline = relational_pipeline( character_unifier_kwargs={"min_appearances": 10} relation_extractor_kwargs={"batch_size": 8}, graph_extractor_kwargs={"min_rel_occurrences", 5} ) novel = load_novel("pride_and_prejudice") out = pipeline(novel) out.plot_graph() plt.show()
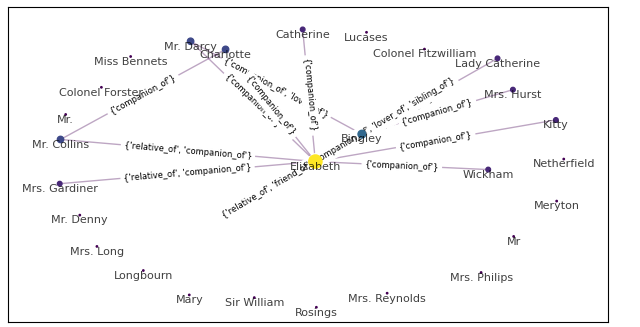
Mmh. I don't remember a lot about Pride and Prejudice, but some of these seem dubious. Time to get back to work.
Future Work
Many things have to be improved. Surely I could tweak many parameters of the T5 training. I don't even know how good is the model! Also, more work is needed to support dynamic networks.
References
Christou, D. and Tsoumakas, G. (2025). Artificial Relationships in Fiction: A Dataset for Advancing NLP in Literary Domains.